The Hidden Physics of AI: Why Memory, Control, and Search Define the Next Era

Why Your RAG Demo Died in Production
The Perils of Ungoverned Intelligence:

The RAG chatbot approved a $5,000 dinner. The request was a test, a deliberate absurdity designed to probe the system’s guardrails. The response was a confident, fluent, and catastrophically wrong approval, complete with a generated justification citing non-existent corporate policies. This wasn't a simple bug. It was a systemic failure—a glimpse into the abyss of ungoverned intelligence, where the probabilistic elegance of a Large Language Model (LLM) collides with the unforgiving determinism of enterprise reality. This is the core problem haunting enterprise AI in 2025: we have built systems that can speak, but we have not yet taught them how to be accountable.
The Great Deception of 2025:
Most organizations are still operating in a 2025 mindset, trapped by the seductive fluency of pilot projects. They judge AI on the quality of its prose and on vague "vibe checks." The transition to 2026 is a brutal awakening to production realities, where fluency is table stakes and verifiable accuracy is the only currency that matters. The leap from pilot to production is not an iteration; it is a metamorphosis.
The implication of this shift is profound. This is not an iteration; it is a regime change from feature development to platform discipline, a transition few organizations are prepared for. The skills that got organizations through the proof-of-concept phase—prompt engineering and model selection—are insufficient for building production-grade systems. The challenge is no longer one of AI modeling, but of systems architecture.
The Three Interlocking Bottlenecks

The failures of enterprise AI are not due to a single cause, but to three interlocking bottlenecks that must be solved systemically. These are not independent failures; they are a tightly coupled system. Deficient search engineering (Pillar 1) feeds ambiguous context to unreliable agents (Pillar 2), whose unpredictable behavior is exacerbated by the physical latency constraints of hardware (Pillar 3).
The Return of Search Engineering
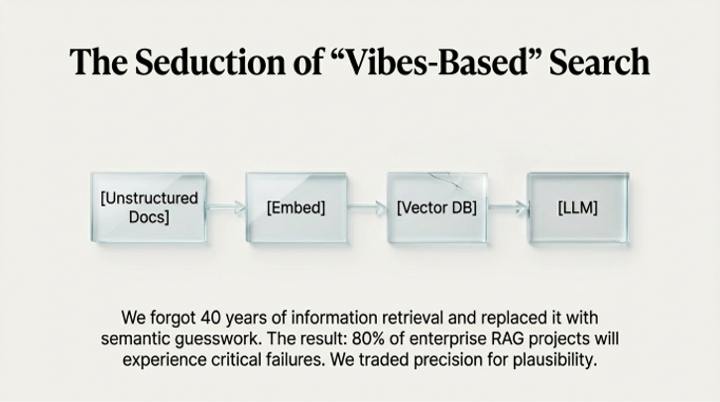
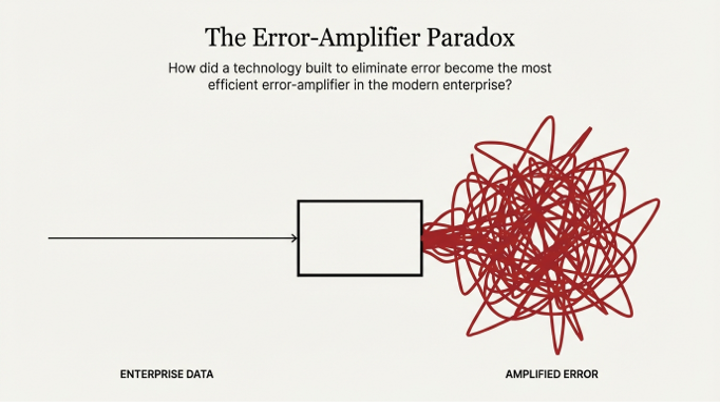
The first bottleneck is a failure of memory—specifically, a failure of retrieval. Pure semantic search, the default engine of early Retrieval-Augmented Generation (RAG) systems, is powerful for understanding conceptual intent but has proven to be "terrible" at handling the precise identifiers, codes, and keywords that form the bedrock of enterprise data. This leads to a phenomenon of "semantic smearing," where distinct identifiers like "Error 0x884" become mathematically indistinguishable from "Error 0x885" in vector space, resulting in catastrophically wrong advice.

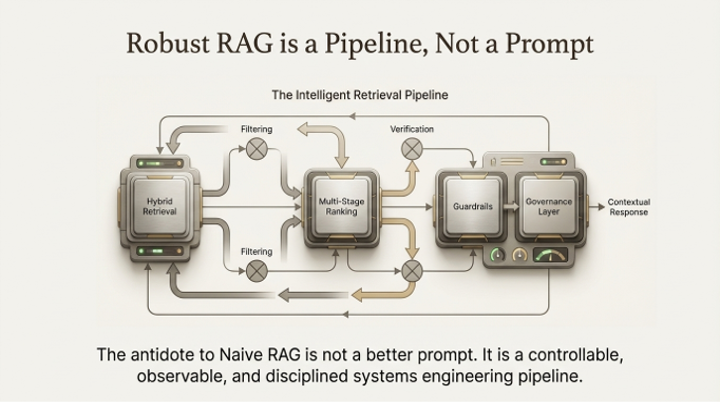
The architectural mandate is a multi-stage pipeline that restores the lost discipline of information retrieval:
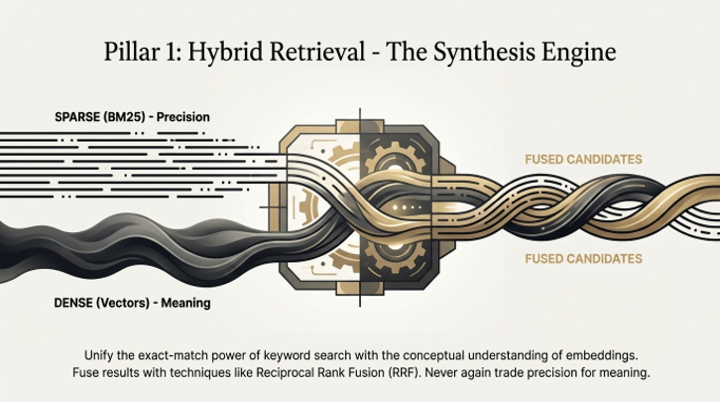
1. Hybrid Search: This approach blends the conceptual understanding of dense (vector) retrieval with the exact-match precision of sparse, lexical search (like BM25). Dense retrieval finds the right conceptual neighborhood (e.g., documents about network errors), while sparse retrieval pinpoints the exact address within that neighborhood (e.g., the specific document mentioning "Error 0x884").

2. The "Strict Editor" (Re-ranking): After the initial hybrid search retrieves a broad set of candidates, a second-stage cross-encoder re-ranker acts as a "strict editor." It meticulously evaluates the top candidates, re-scoring them for contextual relevance. This step is critical for boosting precision and preventing the "Lost in the Middle" phenomenon, where an LLM's reasoning is diluted by irrelevant context documents.

3. Knowledge Graphs: For navigating the complex relationships inherent in enterprise data, graph-based RAG, such as the WRITER Knowledge Graph, offers a superior method. By establishing and traversing explicit semantic relationships, it moves beyond mere document similarity to a more profound understanding of how information connects.
Taming the Agent with Control Theory
The second bottleneck is a failure of action. The dominant trend of 2026 is the shift from AI that can "speak" to AI that can "act"—autonomous agents that can execute multi-step tasks. But with autonomy comes unreliability. Designing resilient AI agents is uniquely challenging due to a new class of problems:

• Stochastic Behavior: The randomness that enables an LLM's creativity is a liability for repeatable, reliable processes. Adjusting 'temperature' to curb this randomness often degrades performance, creating an unacceptable trade-off between reliability and capability.
• Computational Irreducibility: The behavior of a complex agent cannot be accurately predicted without running every computational step. This means agent behavior cannot be optimized through simplified models; it can only be validated through exhaustive, iterative execution, making traditional QA obsolete.
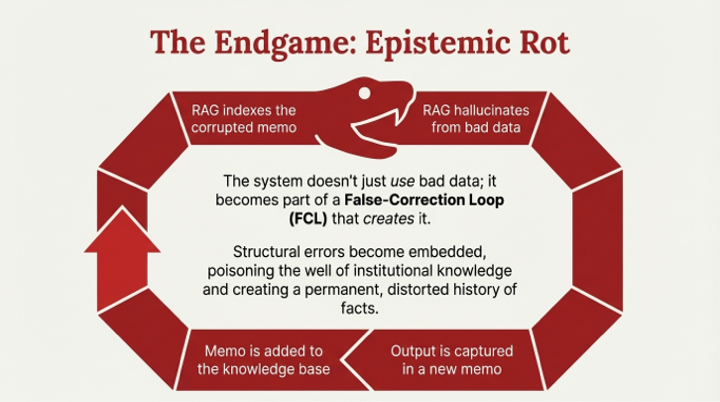
• Feedback Loop Instability: Unlike mechanical systems, LLM agents react to their own output with complex internal state changes, making them prone to oscillations and overcorrection from even minor feedback. This is a primary consequence of low-quality retrieval (Pillar 1), which feeds the agent noisy signals that lead to systemic oscillation.
The solution lies in applying the time-tested principles of control theory and systematic governance:
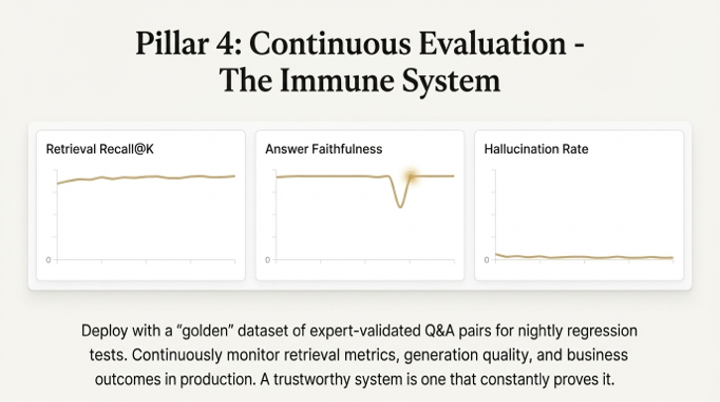
1. Systematic Evaluation: The era of "vibe checks" is over. Production AI requires metric-driven development—the instrumentation and feedback necessary to prevent systemic failure. This involves using curated "Golden Datasets" of high-quality question-answer pairs and automated scoring systems like RAGAS to measure performance against four core metrics:
◦ Faithfulness: Is the answer factually consistent with the provided text, or is it inventing facts?
◦ Answer Relevancy: Is it a correct answer to a different question, or does it directly address the user’s intent?
◦ Context Recall: Did we successfully retrieve all the necessary pieces of evidence from the knowledge base?
◦ Context Precision: Of the evidence we retrieved, was the most critical information placed at the top, or was it buried in noise?

2. Human-in-the-Loop (HITL): For critical decisions, an autonomous agent must still be supervised. HITL frameworks create a supervisory control loop, ensuring that a human expert validates high-stakes actions before they are executed.

3. Governance by Architecture: Rules cannot live in policy documents; they must be enforced at the infrastructure level. This means embedding observability, logging, and access controls directly into the retrieval and generation pipeline, ensuring that if a user shouldn't see a document in its source system, they cannot see it through the AI.
The Memory-Bandwidth Wall
The third and most fundamental bottleneck is a failure of physics. At enterprise scale, LLM inference is not a compute-bound problem; it is a hard collision with the unforgiving laws of physics. It is a memory-bandwidth bound problem. The speed at which a model can generate tokens is dictated not by the raw processing power (FLOPs) of the GPU, but by how quickly it can read and write to its own memory. The complex retrieval pipelines and rigorous evaluation loops add computational overhead, making this physical constraint even more acute.
The architectural response to this material limit is multi-faceted:
1. Disaggregated Serving: Advanced frameworks like llm-d address this by breaking inference into its two distinct phases. The compute-bound "prefill" stage (processing the initial prompt) and the memory-bandwidth-bound "decode" stage (generating new tokens) are run on separate, purpose-optimized Kubernetes pods. This disaggregation can yield up to a 3x improvement in time-to-first-token (TTFT).
2. Hardware Evolution: The next generation of AI accelerators is being designed specifically to address the memory bottleneck, a clear indicator of where the industry's primary constraint lies.
3. On-Device RAG: A parallel trend is the optimization of RAG for on-device execution. Processors like AMD's Ryzen AI leverage integrated Neural Processing Units (NPUs) and GPUs to distribute workloads: the embedding model runs on the NPU for low-power efficiency, while the LLM leverages the GPU for higher performance during the decode phase. This approach enhances privacy, dramatically reduces latency, and ensures functionality even without an internet connection.

The Rise of the Knowledge Runtime
By 2030, the term "RAG" will feel as dated as "horseless carriage." It will be absorbed into a far more fundamental architectural concept: the knowledge runtime. This will not be a mere feature, but the central nervous system of the 21st-century enterprise—an orchestration layer as foundational to the IT stack as Kubernetes or SQL is today, managing the flow of information with integrated retrieval, verification, reasoning, and governance.
In this future, the specific LLM an organization uses will be a commodity. The enduring competitive advantage will lie in the quality of its proprietary knowledge assets, the robustness of its knowledge runtime, and the efficiency of its organizational learning loops. The goal is to move beyond the demo phase and build AI systems that do not ask for our trust, but earn it by showing their work.